


Blockchains have always had a privacy problem by design. A total lack of on-chain privacy for data severely limits what blockchains can achieve and which challenges they can solve. Yet it’s only recently that blockchains have become useful enough (and used enough) that this inherent weakness has been acknowledged by the broader community.
However, while more and more people understand what blockchains are and what problems they can solve, there’s less clarity around how to properly define its privacy problem – and more importantly, what solutions exist. This gap leads to popular misconceptions and myths, with people often attributing more power to certain solutions than what is there in practice. As one simple example, “ZK” (zero-knowledge) tech is primarily useful for scaling, not generalizable privacy, and it’s certainly not a silver bullet. But you wouldn’t know that from reading crypto Twitter or most thought-pieces.
At Secret Network, we focus on practical approaches to achieving privacy in production. We aren’t just trying to solve “transactional privacy” – the much simpler problem of privately sending value from point A to point B. We have a much bigger and much more meaningful vision: allowing anyone to build generalizable and composable decentralized applications with programmable privacy. We’re also proud to be pioneers: Secret Network is already the first L1 blockchain to introduce privacy-preserving smart contracts on mainnet – a milestone we reached nearly 2 years ago.
Because it is so critical to our mission that people not only understand what we are building, but why we are building it, I’ve taken the time to write an in-depth three-part series on Web3 privacy. By the end of these posts, you’ll have a better understanding of the strengths and weaknesses of various privacy technologies, the current landscape of solutions, and why we at Secret have chosen our particular pragmatic and practical approach to privacy. With that said, the goal of this post is to be educational, not to specifically promote Secret, which is why I did my best to present the different solutions as objectively as possible.
For readers who are well-versed, you will see some oversimplifications and generalizations. These were needed to be able to fit this exhaustive overview into a short series of posts. We welcome your feedback and can always make improvements!
If you enjoy this piece and share our mission to create the privacy hub for all of Web3, we welcome you to help us build the Secret ecosystem.


Here’s the structure for this series:
Part 1 (this post): We’ll define the general problem of secure computation, its relation to Web3, and why privacy is the missing link.
Part 2: We’ll give a comprehensive overview of all available solutions, especially their trade-offs, and explain how and why we decided on Secret Network’s current architecture.
Part 3: We’ll bust common myths about privacy solutions, including what privacy guarantees zero-knowledge proofs provide (and don’t).
Let’s dive in! 🏊🏻♂️

Secure Computation
Let’s first start by defining the problem of secure computation, which captures the multi-user computational problem. As we’ll show throughout this post, the secure computation setting is in practice the setting for every blockchain (and non-blockchain!), without privacy.
Imagine an idealized world, where there’s a single, all-powerful and trusted server, and everyone else are clients that utilize this server (send it inputs and receive outputs). If such a server exists and is accessible to all and can indeed be trusted, we can utilize it for any digital service we can imagine. This server would subsume the entire web: it would hold our government’s digital infrastructure, our banking system, all websites, social networks, search engines, applications, etc.
Even in theory this thought might be unsettling, because as we all know, no such entity exists that we would trust to ‘own’ this server, and with it the entire world wide web. However, it is useful to imagine such an ideal version of reality and try to build technical solutions that attempt to emulate it. Clearly, if we can build such solutions (e.g., using blockchains, cryptography) that achieve this ideal, then we would not need to rely solely on social trust – the need to blindly trust organizations, governments, etc. to do the right thing.
So we’ll get back to our ideal framing for now, and assume that such a trusted server actually exists. When we say we “trust” this server, what do we trust this server with? Well, clearly, we want it to protect all of our data and we want to make sure that it provides us with useful services (e.g., it doesn’t tamper with our data and send us back incorrect results to our queries).
In other words, we – the clients – want to make sure that we can protect the privacy of our inputs (including preventing the server from leaking our data to other clients) and also ensure the correctness of the results that we get from such a server. Note that sometimes it’s important that the server also ensures other clients don’t mess up the computation (e.g., by providing bad data).
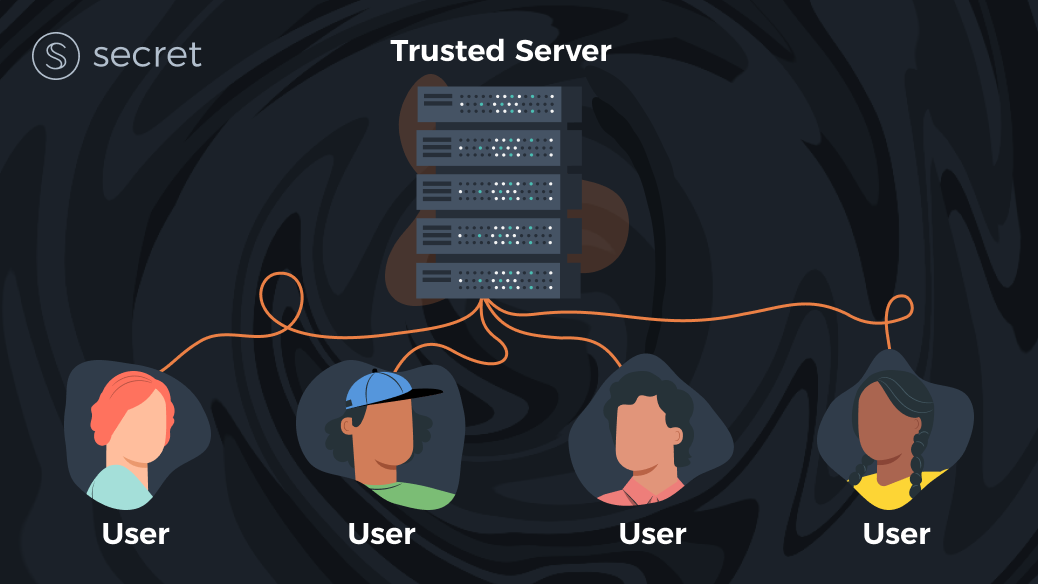
This framework which tries in a multi-client setting to achieve both privacy and correctness is known as the secure computation framing of the digital world, or alternatively – the Secure Multi-party Computation (MPC) model. Solutions to the secure computation problem try to use tools from cryptography and distributed systems to simulate such an all-powerful trusted server, without assuming one exists.
One note about the terminology we would use: both secure computation and MPC are often used interchangeably, but since sometimes they refer to the problem and at other times, as you will later see, they refer to a specific set of solutions, we will continue to address the problem as ‘secure computation’, and use MPC to address a specific class of solutions.
To see why this framework is useful, notice that any operation in the digital world can be essentially summed up into this ideal paradigm. Let’s give a few concrete examples:
- Web-search: Each client can share their search term, the server retrieves all related webpages and returns them to the client.
- Ride-sharing: Both riders and drivers are the clients here – they share their location data with a server, which matches nearby riders and drivers (in this case, both a rider and a driver get the result).
- Voting: Each client casts their vote. The server tallies all votes and publishes the results to all individuals. We also see this example again and again implemented in smart contracts for token community governance, where users can vote proportional to the number of tokens they hold.
- Cryptocurrency token transfer: A server holds the balances of two clients, let’s call them Alice and Bob, that wish to transact. Let’s say Alice wishes to transfer X tokens to Bob. The server computes this, and in most blockchains, lets all clients know (not just Alice and Bob!) their new balances.
For the remainder of this post series, our goal will continue to be to solve for both correctness and privacy. Solving for both in the general-purpose case (namely – for every possible computation/application) turns out to be really hard. Note that there are other properties of interest, but that in many cases they are derived from these two. For simplicity, we mostly ignore anything beyond correctness and privacy in this series.
As we will elaborate more later on, blockchains today (and Web3 in general) solve only half of the secure computation problem. Blockchains ensure correctness, but provide no privacy at all. If you’re familiar with Secret, you would know that this is where we come in – our goal is to provide the ultimate privacy solution for Web3, solving the other half of the secure computation problem.
Web2 vs Web3
Until recently, all technical solutions to the secure computation problem were only theoretical, and the only choice in practice was to simply blindly trust a single entity – just like in the ideal, non-realistic model we described above. This is essentially how Web2 works: clients interact with a specific company’s server (e.g., Google) and in the process allow that company to hoard and use their data in any way they see fit, all in return for receiving some service, which the clients also trust to be done correctly.
These approaches have led to countless data breaches, privacy concerns, and eventually regulation and new laws (e.g., GDPR) which aim to better protect user data from a social perspective. Regulation, however, is only a piece of the puzzle. We need technological innovation as well.
The invention of Bitcoin and blockchain – and later Ethereum – relied on ideas that have existed for decades in academic literature but were the first attempts in the wild of removing that trust in a single entity. A smart contract blockchain is essentially a collection of many computers that, while individually untrusted, can collectively be trusted (given some assumptions on maximal collusion) to compute any functionality correctly. The reason this is extremely powerful is because this solution is generic – it can be used for everything. In practice, it’s an open question how much we can scale blockchains so that they can actually replace centralized solutions, but if we indeed can – wouldn’t it be great to build a better web using them? That’s the core idea behind Web3.
Blockchains have gained immense popularity for their ability to solve for correctness, as we mentioned earlier, which is half of the problem we defined for secure computation. Basically, this means that whatever is computed on the blockchain can be trusted to be correct and that no one (client or server) has tampered with it.
It’s therefore not surprising that the use cases where blockchains have found the most product-market fit to date are financial use cases, where trust is in short supply. For example, while we may trust Google to send us back the correct search results to our query (incentives are aligned), will we trust it to manage a global currency and ledger? Probably not.
Okay – so we have established that the de-facto property blockchains solve for is correctness, the next question is: what about privacy? As it turns out, blockchains by design provide no privacy whatsoever. In that sense, they are strictly worse than the Web2 model:

Without getting too technical, the main intuition about why blockchains are useless when it comes to privacy relates to how they operate. In a nutshell, a blockchain guarantees correctness by letting many servers execute computations together and verify that they all reach the same conclusion. Since in permissionless blockchains anyone can run a server, it immediately follows that anyone in the world is able to see everyone’s data, whereas in Web2 only a single entity gets to see that data (which is already bad enough).
And now we get to the heart of the matter. As it turns out, solving for privacy after you solved for correctness is hard!
Solving for privacy is hard
Before we explore the solution space (that’s Part 2!), it’s important to understand intuitively why solving for privacy is hard, and why it’s probably harder than correctness. From this point and on, we’ll start to get a bit more technical, but we’ll try to keep it high level enough so that everyone can understand.
For correctness, blockchains provided a great solution: we let many servers re-run the computation, and they can check each other and make sure that no one is cheating. There are other solutions for proving correctness, but at the end of the day they all fall back to the idea that someone else can verify your work.
However, with privacy, we are asking for something that’s completely counter-intuitive – we are asking a server (or several servers) to compute over data they can’t see. If they can see the data, they can leak it, and that requires trust that we don’t want to have. In practice, there are several cryptographic solutions to this problem, which we will soon explore – but like everything else in life, they come with trade-offs, some of which remain very serious.
More importantly, data leakage is a silent form of a security attack: by definition, we or others may not be able to know that data was leaked. Even if we do end up finding our sensitive data uploaded somewhere else on the web, it might be impossible to pinpoint where the leakage occurred and who leaked it. This is very different from correctness, where ‘loud’ attacks (i.e., you have to actively break the protocol and others can observe it) allow you to more easily identify malicious actors.
This issue of ‘silent’ vs ‘loud’ attacks is probably the biggest contributor to why building privacy-preserving solutions is so hard, because we can’t incentivize against that kind of behavior.
Now that we are starting to understand the problem of privacy in Web3, it’s time to dig deeper into what solutions are available, what the tradeoffs are, and how Secret is solving this very meaningful problem with a unique architecture that is privacy-preserving, programmable, and pragmatic.
Thanks for reading Part 1 of this series on Web3 privacy. Part 2 is now live and can be found here:
Guy Zyskind
We’ve thought deeply about these issues for the past years, and Secret Network is proud to continue leading the charge towards secure computation in the blockchain space. If these ideas interest you – and if you’re convinced of their importance – please join us in building solutions and technologies that can help us secure the decentralized web and scale Web3!
If you’re an app developer, check out our resources here. (Secret uses Rust!)
If you’re anyone passionate about ensuring Web3 users has the data privacy protections they need and deserve, consider becoming a Secret Agent! It is our mission to make sure the decentralized web we’re building is one that truly empowers – and one that is accessible to all. From awareness and education to international growth and university relations, there are many ways to help contribute to the expansion of the Secret ecosystem and the global availability of privacy technologies in Web3.
Check out the Secret Agents program and join one of the best and most committed communities in the entire blockchain space!

Onwards and upwards towards privacy!
Guy Zyskind is the founder of Secret Network, CEO of SCRT Labs, a former researcher at MIT, and author of some of the most highly cited blockchain privacy papers (including “Decentralizing Privacy,” written in 2015).
