


Welcome back to Beyond ZK – a series of blogs from the Secret Network community exploring pragmatic solutions to Web3 privacy.
In the first part of this blog, we took a first look at the problem of secure computation in Web3. Blockchains are an awesome tool for correctness – but they have important tradeoffs and complications regarding privacy. As blockchains are not privacy-first solutions, Web3 may be worse in terms of privacy than Web2 ever was. A lack of private computation in blockchain means everyone can see all your data, forcing developers to build in a narrow design space that doesn’t allow them to create truly useful decentralized applications.
In Part 2 of this blog series, we’ll dive deep into the cryptography toolbox and look for potential pragmatic solutions to the privacy problem introduced by blockchains. The diverse set of methods we’ll examine today are:
- Partial or Fully Homomorphic Encryption (HE/FHE)
- Secure Multi-Party Computation (MPC)
- Trusted Execution Environments (TEEs)
- Zero-Knowledge Proofs (ZKPs)
In cryptography, there’s rarely an “optimal” method. Every solution mentioned here has multiple constructions and can be used alone or in tandem with other solutions to solve interesting problems on a case-by-case basis. Each construction and combination comes with trade-offs and relative advantages.
In this post, we are interested in how the methods mentioned above can be individually used to solve for the generalized problem of privacy: how to run any computation in a blockchain setting with correctness, while ensuring that the underlying nodes / validators / miners can’t see the data they’re computing on.
This state of generalized private compute will be referred to as secure computation in the remainder of this blog. As we go through this exercise, we’ll also walk through some solutions to specific privacy problems in the blockchain space (e.g., sending tokens privately).
Let’s go! 🚀
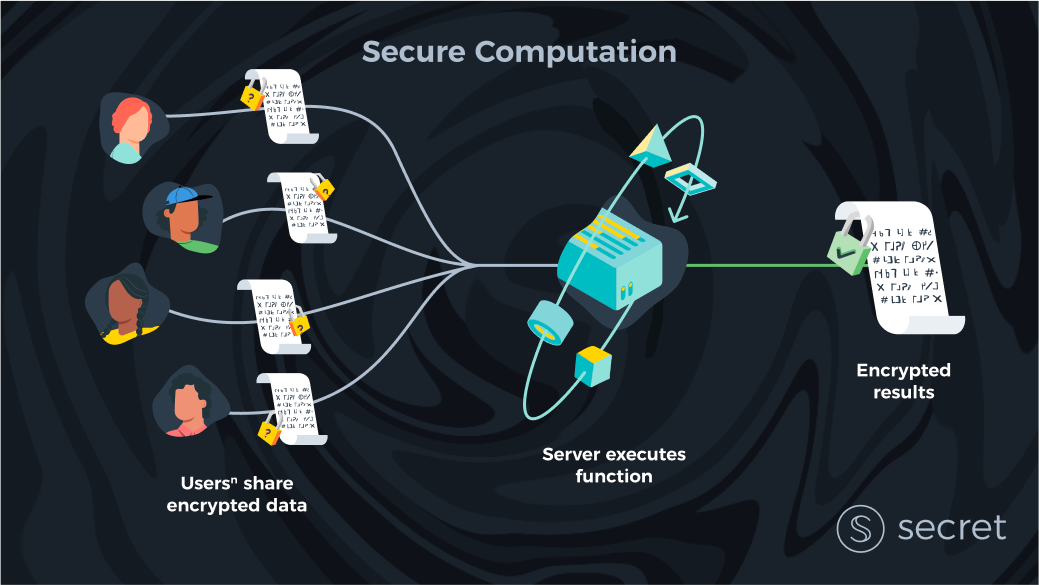
Fully Homomorphic Encryption
Fully homomorphic encryption (FHE) is an idea that’s easy to understand but extremely hard to implement. As a matter of fact, while the original idea was proposed in 1978 by Rivest et al, it wasn’t until 2009 when Craig Gentry built the first construction of such a scheme. This breakthrough ushered in a decade of renewed interest and research into fully homomorphic encryption schemes, which greatly improved the efficiency of the original construction by many orders of magnitude.
So what exactly is FHE? FHE is an encryption scheme that enables anyone to compute over encrypted data without having to decrypt it first. Recalling our first post in this series, let us imagine a simplified version of the ideal world again in which there is a single client/user (instead of many) and one server. The problem in this ideal world is that we can’t trust that one server to protect the privacy of our data. Well, with FHE, this seems trivial: a client can send her data to a server encrypted, and the server can then compute over her data without viewing the raw data. Job done?
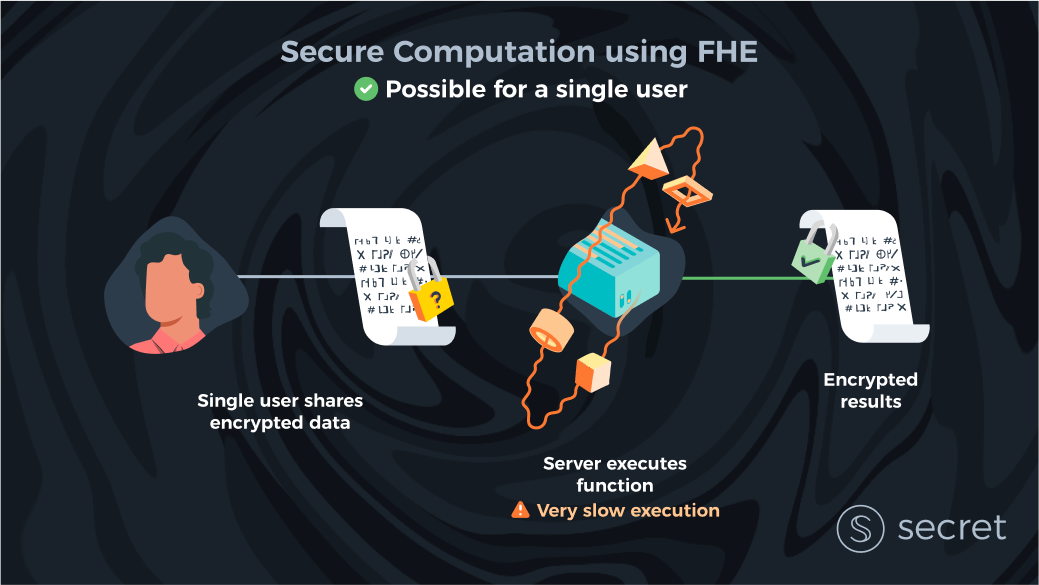
Limitations of FHE
Not quite. First, FHE, to date, has been extremely inefficient. FHE is, in fact, the slowest of all privacy-preserving technologies we know. However, the efficiency of FHE computation has been improving at an incredible rate, and specialized hardware (CPU → GPU → FPGA → ASICs) will improve computation speed further by several orders of magnitude in the next decade. This efficiency increase is the most important reason that the Secret community has been looking into FHE again as a potentially viable solution (as mentioned in the Secret 2.0 forum post).
However, it’s important to clarify that even in 5-10 years, it’s most likely that using FHE capabilities will only make sense for certain use cases or for certain parts of smart contract execution. For example, you may want to use FHE to store and operate on extremely sensitive (and small) data, like cryptographic keys or SSNs.
FHE with multiple clients
So FHE is a seemingly simple, albeit computationally expensive, solution when the computation problem involves only one client. Then the question becomes: how do we introduce a second client to this secure computation problem? It should be evident that, in practice, the secure computation setting with multiple clients is the more interesting setting since many scenarios involve combining data from multiple parties.
In a world with only one client, she herself could rent a strong cloud server and run computations instead of trusting others with her data. In that single-client case, the problem of trusting an external party to keep your data private and run computations for you correctly seems to be less important in practice.
Adding this second client is not a trivial change and leaves many technical people scratching their heads. First, let’s imagine there are only two clients in the world. Both clients have their own input and want to compute a function over their inputs. Per usual, both want privacy (i.e., neither the server nor the other client learn anything about their data). With ‘pure’ FHE, it’s unclear how to do this as each client used their own key to encrypt their data. FHE is awesome, but it can’t magically compute over data encrypted with different keys. So how do we solve this?
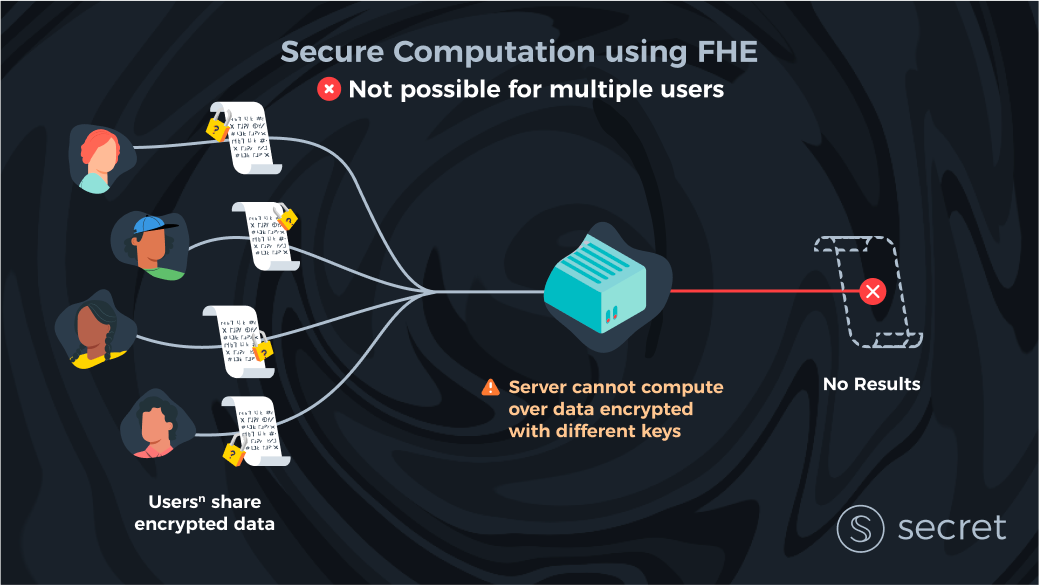
Partial Homomorphic Encryption (PHE)
The honest answer is that many methods are needed to be used to solve this problem. In addition to fully homomorphic encryption, which can compute any arbitrary function over encrypted data, there are many partially homomorphic encryption schemes (HE or PHE). These partial schemes can compute specific functionalities—usually either addition or multiplication—but not both (note that all functions can be reduced to addition and multiplication operations). These partial HE schemes were invented decades ago and are much more efficient, and they may be sufficient for a limited set of use cases, but they are not sufficient for the general case of secure computation.
Several networks aim to use such a partial scheme like PHE to achieve privacy (e.g., Penumbra and Dero). However, it is important to understand that they cannot, by definition, support general-purpose smart contracts. The applications of these techniques for privacy-focused blockchains is novel, but the use cases it can support are quite limited.
There are non-trivial ways to extend the range of applications you can support with a partial solution like this, but that would require deep expertise in cryptography. These applications often bring other hidden trade-offs that are hard to reason about. For that reason, PHE will likely never allow developers to build arbitrary applications with privacy.
So if FHE or partial HE solutions alone can’t solve for the multi-client secure computation problem… what can?
Secure Multi-Party Computation (MPC)
Multi-party computation (MPC) refers to both the problem—doing arbitrary computations over encrypted data provided by multiple parties—and one of the methods that is aimed at solving it.
To avoid confusion, we’ve been careful throughout this post to refer to the problem as ‘secure computation’ and reserved the use of MPC to refer to a specific range of solutions that directly solve this problem.
There are generally two types of MPC solutions: those based on Linear Secret Sharing and those based on Garbled Circuits. Describing these solutions is out of scope for this post, but the trade-offs and security model they operate in are important to our understanding.
MPC with multiple clients
MPC solutions can be seen as the distributed systems (or, if you will, the “blockchain-ish”) solution to computing over private data. In these schemes, instead of trusting a single server, we have several untrusted servers that jointly run a computation over client data. Changing the trust assumptions greatly increases the solution space. MPC solutions are developed with multiple clients in mind, meaning there are no theoretical problems with servers combining data from any number of clients, like in an FHE setting.
Note that the way to turn an FHE scheme for one user into one for multiple users is to actually “MPC” it by splitting a single FHE encryption key into shares shared by all the servers. This is called Threshold FHE, which mixes MPC with FHE. From a security perspective, it reduces to the same security model of MPC. The TL;DR of this is that using FHE for multiple users is essentially another form of MPC. We will explore this in more depth in a future post.
Limitations of MPC
Of course, there are trade-offs to using MPC as well. The main trade-off is that MPC relies on “security by non-collusion.” Using FHE allows the client to keep her secret encryption key without the server ever getting access to her data. But with MPC, we need at least one server to be honest, because if all servers collude, they can trivially reconstruct the private data. This is actually by design because MPC solutions don’t contain keys.
Instead, MPC hides the data by giving each server an “encrypted” share of the data so that you’d need all shares to ‘“decrypt” the data. Additionally, each share alone does not reveal anything about the plaintext data. From this, it should be clear that the collusion requirement is inherent, and at least one party needs to act honestly.
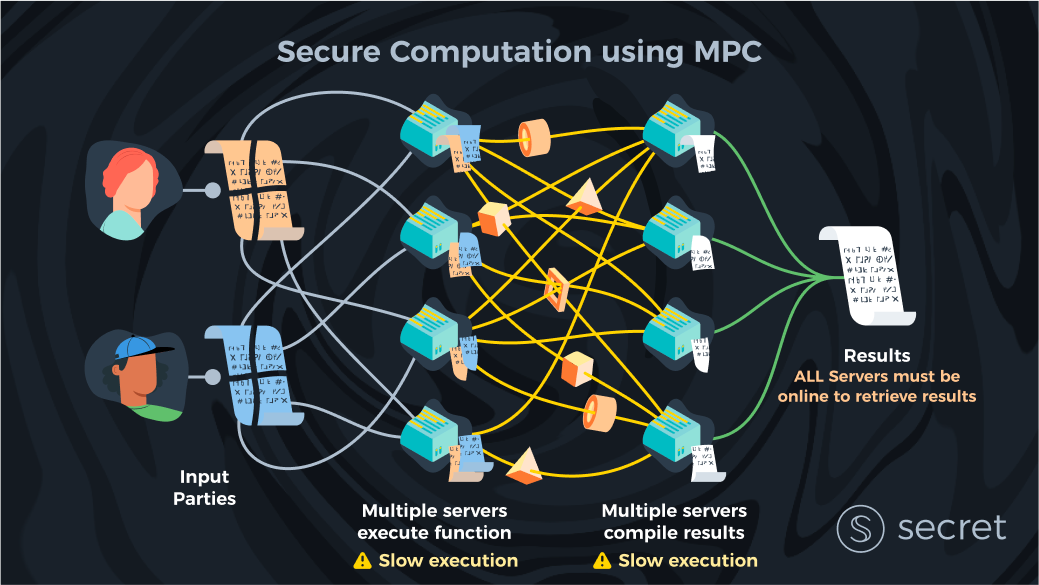
In practice, one could tailor the collusion thresholds to optimize for either liveness or privacy. In the above example, where all key shares are required to reconstruct the data, we obtain maximum privacy. However, it only takes a single server to mount a DoS attack against the entire system. This is because it takes only one server not responding to a client’s request, and the result can’t be computed. We can choose however to require only ½ (or any arbitrary amount) of the key shares instead, meaning that we require the majority of servers to be honest and not collude to be able to deliver a computational result.
There’s a lot more to say about this topic, but for now, it is important to notice the similarity between blockchains and MPC solutions. Both are distributed systems that base their security on anti-collusion assumptions, meaning there is an inherent trade-off between correctness, liveness, and privacy. Now the question remains: which is more important?
MPC for privacy vs correctness
Now that we’ve considered the trade-off between correctness and liveness, let’s address head-on why privacy is likely harder than correctness in MPC systems. Correctness is verifiable—if a transaction is tampered with, this is either seen or consensus even stops. However, one cannot verify collusion attacks on privacy, making it a ‘silent’ attack. If servers in the system share their key shares outside the bounds of the system, they can collude and we will never know that they reconstructed the data. This silent attack vector makes solving for privacy with distributed systems more challenging than ensuring correctness.
To eliminate this attack vector, we can aim to have as many servers as possible run the computations thereby avoiding collusion attacks. Sadly, MPC scales poorly with the number of parties and increasing the number of servers hinders liveness. It therefore seems that MPC alone is not enough and other technologies that make collusion hard need to be implemented.
Complicating collusion
One way to make MPC collusion hard would be to force all servers in the distributed system to use Trusted Execution Environments (more on this below). We’re aiming to implement such a cross-method solution on the current Secret mainnet, bringing additional safety to our privacy system.
Alternatively, one can complicate collusion by working in a permissioned setting, where servers are (partly) trusted and can be re-identified if a data leakage occurs. This is the direction Partisia Blockchain appears to be taking: an off-chain set of semi-trusted nodes execute private computations, and the blockchain only stores and verifies the state.
Other methods include the design mentioned in my graduate thesis and the original Enigma whitepaper. In these papers, a mechanism is proposed for sampling small committees to run computations. If done carefully, we can design a blockchain that has many different servers, but for each computation (or set of computations) selects a small number of parties to actually do the heavy lifting. While this solution sounds promising and it does asymptotically scale really well, it’s not practical for many reasons that mostly come back to having to trust a single or multiple parties.
We’ll dive deeper into these types of combinations of techniques in Part 3 of this blog series, so stay tuned!
Trusted Execution Environments
So far, all the solutions to the secure computation problem we’ve mentioned have been cryptographic in nature. “Cryptographic” often means “cool” in the eyes of developers, but “cool” doesn’t always mean efficient, pragmatic, or even feasible. So far, the only purely cryptographic method that could solve the secure computation problem is MPC, which still assumes that the servers (e.g., our blockchain validators) don’t or can’t collude to reconstruct the data. So let’s take a look at another potential solution to the problem at hand.
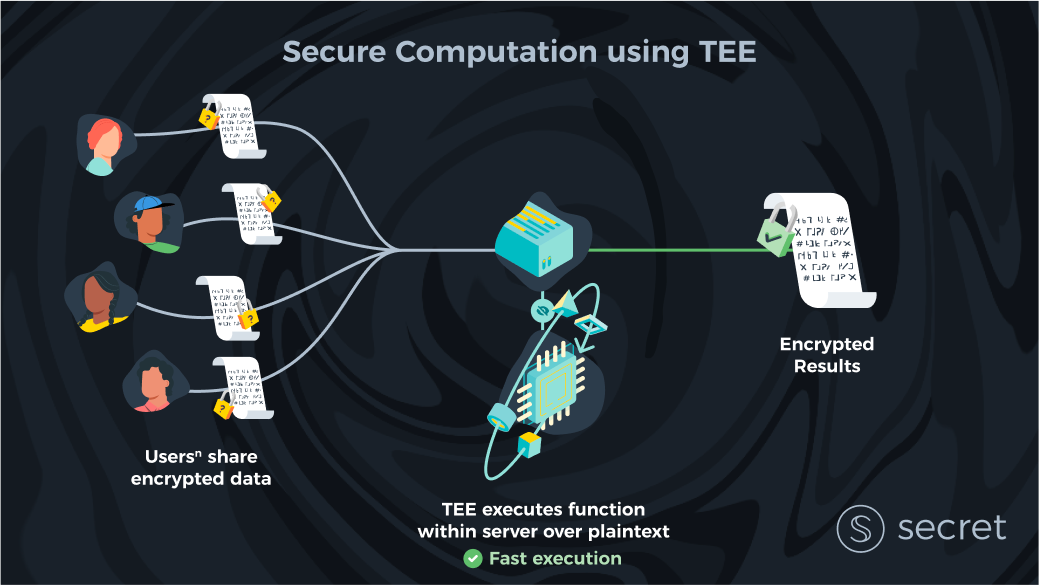
A Trusted Execution Environment (TEE), in simple terms, is a region in the processor that is separated from the rest of the CPU. This region can store data (e.g., encryption keys) and run computations that cannot be tampered with by the host of the machine. Also, the host cannot extract any data stored in that region (at least, in theory).
How TEEs solve for privacy (and correctness)
TEEs can solve for privacy and correctness by requiring our server (or in the blockchain setting, servers) to execute all computations inside their TEE. In addition, we can ask clients to encrypt their input data using a key that’s also only available in the servers’ TEEs.
With this design, no one—not even the host who owns the servers— has access to the clients’ data. This is because data is only ever decrypted and computed over inside the TEE. For more information on how such a system works in practice and how encryption keys are kept safe, take a look at the Secret Network technical documentation.
Another way to think about TEEs is as a hardware approximation of the ideal world we described in Part 1, where there’s a single trusted server that can run computations both correctly and privately. However, making the most out of TEEs is much more complicated than what we described here. To prevent censorship or DoS attacks, it’s still best to use TEEs in a distributed system like blockchain instead of relying on a single server.
Because TEE systems obtain security via hardware reliance as opposed to pure cryptography, they are very efficient. While cryptographic solutions are generally orders of magnitude slower than computing in the clear, in most cases TEEs have less than 40% overhead in computation time. This mainly comes from the requirement to decrypt input and re-encrypt output to preserve privacy.
Drawbacks of TEEs
The main drawback with TEEs that worries users is the possibility of side-channel attacks. In recent years, researchers have shown how they can extract information from TEEs mostly using speculative execution, a method used by all modern processors to gain efficiency. While most of these problems can be solved in software or hardware and are difficult to exploit in practice, they do present a disadvantage compared to pure cryptographic techniques on this specific vector of attack. Architectural bugs (which can impact any type of hardware, not just secure enclaves) are also possible and pose a serious risk, which should not be ignored.
With these tradeoffs considered, TEEs still currently stand as the best practical solution, especially for high performance computations on low sensitivity data. Even when the core of a potential solution is cryptographic in nature, TEEs are key to enhancing security and can help prevent collusion while boosting scalability. This is why Secret is continuing to build with TEE technology and implement it in our solutions.
Zero-Knowledge Proofs
Last but not least, we want to touch on the use of Zero-Knowledge Proofs (ZKPs) for the Web3 privacy problem. As a network, we very often get questions about how project X compares to Secret Network, where X is a project that utilizes some technique based on Zero-Knowledge Proofs. If this is the case, why did we leave ZKPs until the end of this long post?
Well, as it turns out, ZKPs are not really a privacy solution—at least not to the big privacy problem that we’ve been describing in this series of posts. But before we can explain why, we need to briefly explain what ZKPs are.
A zero-knowledge proof system is a two-party protocol in which a prover P wishes to prove to some verifier V that some statement is true, without revealing anything else. Without getting too formal, the prover often supplies a proof that says ‘I computed y=f(x) correctly,’ where the verifier knows the function f and the output y, but not the input data x.
For example, imagine Alice has a certified digital passport and wants to prove to the bartender she’s over 21 without revealing her date of birth. In this case, f is the computation ‘Am I over 21?’, x is her certified passport which includes her date of birth, and y is the answer (True or False). Using ZKPs, Alice can achieve this.
ZKPs have existed for several decades. In the last decade, a special form of ZKPs was introduced—one that makes the proof itself extremely small (there are several variants of this with different trade-offs) and the verification extremely fast and efficient. These proofs are also non-interactive. This means that a prover can generate a proof in one go, send it to the verifier, and the verifier can independently run the verification without contacting the prover ever again. Generating the proof itself is expensive, depending on the complexity of the computation, but this has also seen great improvements in the last few years.
Why ZKPs work better for scaling than privacy
These non-interactive and light verifier-side computation properties make ZKPs a great way to scale blockchains off-chain.
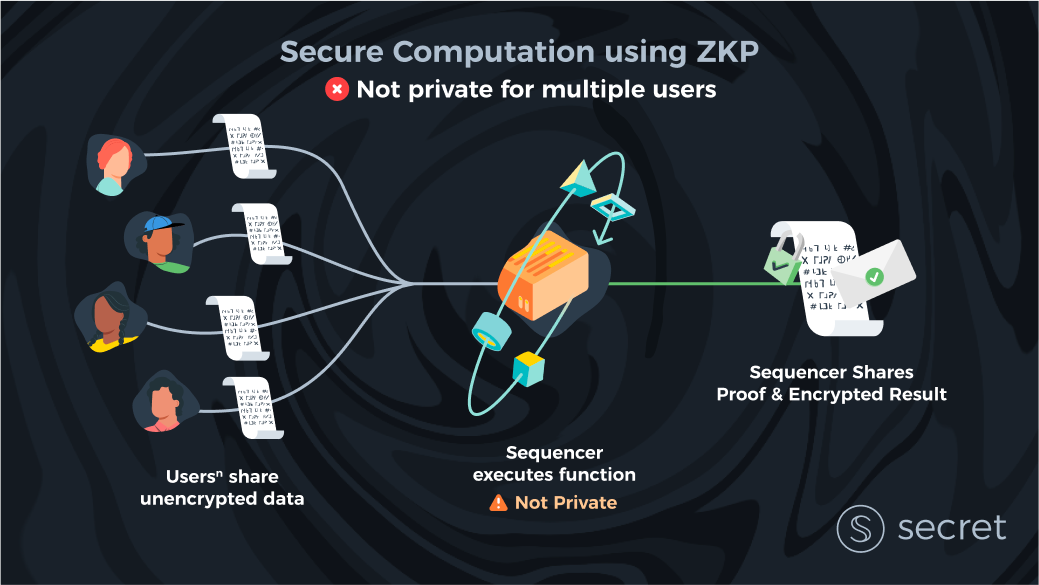
The main idea is fairly simple: have a centralized party (often called the sequencer) execute all transactions (and computations) off-chain. This means that clients interact directly with this sequencer instead of the blockchain and send it their non-encrypted input data. The sequencer, after running all computations, produces a succinct proof and sends it to the blockchain alongside the outputs (usually the updated state). The blockchain, which acts as the verifier, verifies that the proof is correct, and if so, applies the state changes without learning the clients’ data directly. All general-purpose blockchain ZK solutions use this scaling method, including zkEVMs (of which there are a few), Aleo, Starkware, and others.
But while ZKPs are a great scaling tool, it should be clear why ZKPs offer a limited privacy solution for Web3. Users need to trust a centralized sequencer (just like in Web2) with all of their data. Similarly, if we want to allow multiple sequencers (to distribute the trust assumption), the privacy situation only gets worse.
The narrow use of ZKPs for privacy
However, in certain situations one can use ZKPs to provide privacy. An example of this is Zcash, where each user has to prove that they are not double-spending coins. They have to prove this without revealing to the blockchain how many coins they have or are currently transferring to whom. Generally speaking, the key to using ZKPs in this way is that each user does a computation on their own part of a globally shared private state. They then use a ZKP to prove to the blockchain that they didn’t cheat.
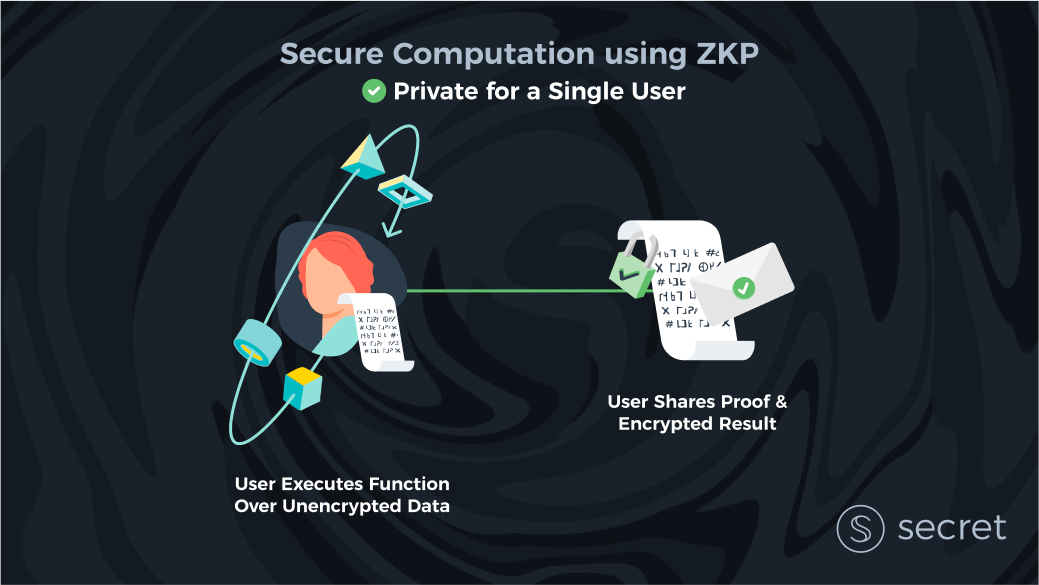
But we need to be clear: this technique is limited to very specific use cases, not to generalizable secure computation. For example, an auction comparing clients’ private bids cannot use this technique, because it has to make direct use of the inputs of multiple clients as part of the computation. Clients would have to share data off-chain to do proofs like this and thereby forego their data privacy. Moreover, defining smart contracts in a way that facilitates this requires deep cryptographic knowledge and often has other trade-offs in terms of deployment (e.g., forcing clients to do heavy-duty cryptography locally).
The takeaway from this is that ZKPs are more of a scaling solution than a privacy solution. ZKPs can solve for privacy in some use cases that are limited to single clients, such as transactional privacy. More complex computations require significant tailoring of circuits and might never be feasible unless we fully trust sequencers to safeguard user information. ZKPs can therefore not solve the secure computation problem on their own. However, they can be good additional tooling for scaling slower private baselayers, or as a complementary tool for MPC and FHE. Combining techniques in this manner is something we will cover in a future post.
Summary
At this point, we’ve scanned through pretty much the entire privacy toolbox (except differential privacy and some other unrelated solutions). While each solution presented here has decades of research and many thousands of papers behind it, the inherent trade-offs remain the same, and we can summarize them here.
As a reminder: the general problem we’re interested in is that of secure computation, which asks the question of how multiple clients can run computations over their shared data while ensuring both correctness and privacy. We explained that blockchains only solve the first half of the problem (correctness), and presented several possible technologies that solve the second problem (privacy).
We summarize the available solutions and their trade-offs in the table below. Note that this is an oversimplification of these tools and the assumptions that they make—our goal is to only present the biggest security trade-offs and concerns when choosing one (or more) of these tools. For that reason, we ignore underlying cryptographic assumptions, quantum security, or trusted setup assumptions which may or may not exist based on a specific construction.

The table above “compresses” the dimensions of interest to the most concerning security assumptions, efficiency (split between local computation and network costs), and how easy it is for developers to use this tool in practice.
From this, the most important question one should ask is: what’s a better assumption to make in practice? That validators will never collude to leak the data (Threshold FHE/MPC solutions)? Or is it better to trust one centralized party to store and see all the data (ZKP solutions)? Or, is it best to trust that side-channel attacks (or hardware bugs that expose vulnerabilities) against TEEs can be efficiently protected against?
It might be the case that there’s no clear answer to this question, but it should at least get you thinking. At this moment in time, it appears like TEEs still present the only practical solution for low-to-mid-sensitivity and high-performance use cases. For anything beyond, it seems that the combination of MPC/Threshold FHE with TEEs are the way to go. With Secret 2.0, we will venture in the direction of mixing different techniques in the stack to give developers the choice that best fits their use case.
In Part 3 of this “Beyond ZK” series, we’ll dive deeper into a modular privacy stack for blockchain and what it enables for the secure computation problem. If you’re interested in an early look at modular privacy designs, feel free to read our blog post on Secret 2.0, explaining the evolution that’s next for Secret Network!
What’s next?
We’ve thought deeply about these issues for the past years, and Secret Network is proud to continue leading the charge towards secure computation in the blockchain space. If these ideas interest you – and if you’re convinced of their importance – please join us in building solutions and technologies that can help us secure the decentralized web and scale Web3!
If you’re an app developer, check out our resources here. (Secret uses Rust!)
If you’re anyone passionate about ensuring Web3 users has the data privacy protections they need and deserve, consider becoming a Secret Agent! It is our mission to make sure the decentralized web we’re building is one that truly empowers – and one that is accessible to all. From awareness and education to international growth and university relations, there’s many ways to help contribute to the expansion of the Secret ecosystem and the global availability of privacy technologies in Web3.
Check out the Secret Agents program and join one of the best and most committed communities in the entire blockchain space!


Onwards and upwards towards privacy!
Guy Zyskind is the founder of Secret Network, CEO of SCRT Labs, a former researcher at MIT, and author of some of the most highly cited blockchain privacy papers (including “Decentralizing Privacy,” written in 2015).
